
The Reliability and Classical Measurement Theory. In Classical Measurement Theory, reliability refers to the consistency or stability of a measurement, indicating the extent to which a test or measure produces similar results across different administrations or different items within a test. It essentially represents the proportion of the observed variance in a measurement that is due to true score variability, rather than measurement error.
What is Reliability and Classical Measurement Theory
Classical Test Theory Reliability Validity focuses on the definition (i.e., use and interpretation) of the true score, while reliability focuses on the random error. The error is the sum of all random effects, while the true score is the sum of all consistent effects.
Classical Measurement Theory Introduction
Reliability is a fundamental concept in classical measurement theory, which underpins the consistency and stability of measurements obtained from various instruments. This concept is crucial for ensuring that any self-report or norm-referenced measure of attitudes, behaviors, or other psychological constructs produces consistent and dependable results. Understanding reliability involves exploring its various forms, methodologies for assessing it, and its implications for research and practice.
What is Reliability?
Reliability refers to the consistency of responses obtained from a measurement instrument. In classical measurement theory, the observed score of an individual is considered a combination of their true score and measurement error. The true score represents the actual level of the attribute being measured, while the measurement error reflects the discrepancies between the observed score and the true score due to various factors.
Maximizing the reliability of an instrument helps in reducing the random error associated with scores, but it is essential to remember that validity also plays a role in minimizing systematic errors. Reliability, therefore, ensures that an instrument consistently measures the attribute it is intended to measure.
Errors in measurement can be categorized into random and systematic errors:
- Random Errors: These are unpredictable variations in scores due to factors such as mood, fatigue, or environmental conditions during measurement.
- Systematic Errors: These arise from biases inherent in the measurement instrument or procedure, such as poorly designed questions or consistent rater biases.
Reliability is assessed by examining the consistency of an instrument’s scores across different contexts, times, and items. This involves evaluating how well an instrument performs in maintaining the same results across different occasions or different forms of the same test.
Forms of Reliability
Reliability can be assessed through two primary forms: stability and equivalence. Each form addresses different aspects of consistency and is evaluated using specific methodologies.
Stability Reliability
Stability reliability pertains to the consistency of measurements over time. This form of reliability is assessed through test-retest procedures. In a test-retest reliability assessment, the same instrument is administered to the same subjects at two different points in time, often separated by a few weeks. The scores from these two administrations are then compared to determine the consistency of responses.
Challenges with Stability Reliability:
-
- Conceptual Change: One issue with stability reliability is that the concept being measured might change over time. For example, if an individual’s attitude toward a particular topic evolves between test administrations, the observed instability might reflect true changes rather than inconsistencies in the instrument itself.
- Interval Selection: The time interval between test administrations must be appropriate for the concept being measured. A two-week interval may not be suitable for all constructs, and selecting an interval that reflects the theoretical nature of the concept is crucial.
- Equivalence ReliabilityEquivalence reliability involves assessing the consistency of responses across different forms of an instrument or across different items within the same instrument. This form of reliability can be evaluated using two main approaches: alternate forms and internal consistency.
- Alternate Forms Reliability: This approach involves creating two or more parallel forms of the instrument that are designed to be equivalent in content and difficulty. Subjects complete each form at the same time, and the scores are compared to assess the equivalence of the forms. The challenge with this approach is ensuring that the alternate forms are truly equivalent, which requires careful development and validation of the forms.
- Internal Consistency: This approach evaluates the consistency of responses within a single instrument by analyzing how well the items measure the same construct. Internal consistency is often assessed using statistical techniques such as split-half reliability and Cronbach’s alpha.
Stability and Its Problems
Stability reliability is highly valued for its ability to measure the consistency of an instrument over time. However, there are several problems associated with this form of reliability:
- Conceptual Changes: If the concept being measured changes over time, the observed instability might not necessarily reflect issues with the instrument but rather genuine changes in the construct.
- Interval Length: The choice of time interval between test administrations can influence stability reliability. Short intervals may not capture long-term changes, while longer intervals might introduce other factors that affect the consistency of responses.
Interrater Reliability:
In cases where raters or observers are involved, interrater reliability assesses the consistency of ratings across different individuals. This form of reliability ensures that ratings remain stable across raters and are not influenced by individual differences or biases.
Equality and Its Evaluation
Equivalence reliability can be evaluated in two primary ways: through parallel or alternate forms and internal consistency.
- Parallel or Alternate Forms: This technique involves creating and comparing two equivalent forms of an instrument. The goal is to ensure that the forms measure the same construct and produce similar results. This method requires the development of parallel forms that are equivalent in content and difficulty. The scores from these forms are then compared to assess their equivalence.
- Challenges: Obtaining truly parallel forms can be challenging, and ensuring that the forms are equivalent in all aspects is a complex task.
- Internal Consistency: This approach focuses on the consistency of responses across items within the same instrument. Internal consistency is typically assessed using statistical measures such as split-half reliability and Cronbach’s alpha.
- Split-Half Reliability: This method involves dividing the items on a scale into two halves and comparing the responses on each half. High correlations between the two halves indicate good internal consistency.
- Cronbach’s Alpha: Developed by Lee Cronbach in 1951, Cronbach’s alpha is the most commonly used measure of internal consistency. It computes the ratio of the variability between individual responses to the total variability in responses. The formula calculates the proportion of the total variance attributed to real differences between subjects versus measurement error.
Cronbach’s (1951) Alpha to Measure Reliability
Cronbach’s alpha is a widely used statistic for assessing the internal consistency of a measurement instrument. The formula for Cronbach’s alpha is:
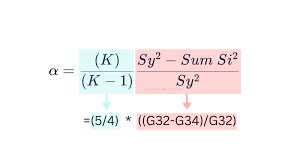
Where:
- NN is the number of items on the scale.
- rˉ\bar{r} is the average inter-item correlation.
Cronbach’s alpha values range from 0 to 1, with higher values indicating greater reliability. A value of 1 represents perfect reliability with no measurement error, while a value close to 0 indicates poor reliability.
Guidelines for Cronbach’s Alpha:
- Well-established instruments typically have alpha values above 0.80.
- Newly developed instruments should aim for alpha values of 0.70 or greater.
Limitations:
- Redundancy: Extremely high alpha values may indicate redundancy among items. In such cases, some items may be unnecessary, and reducing the number of items could improve the instrument’s efficiency.
- Sample Size: Cronbach’s alpha is influenced by the number of items and sample size. Increasing the number of items can artificially inflate the alpha coefficient, while small sample sizes can lead to biased estimates.
- Assumptions: Cronbach’s alpha assumes that items are parallel and have identical true scores. When this assumption does not hold, alpha may be a lower bound to reliability. In such cases, other coefficients based on principal components or factor analysis, such as Theta and Omega, may be more appropriate.
Item Analysis: Achieving a high alpha value does not complete the evaluation of internal consistency. It is essential to conduct item analysis to examine the fit of individual items with the overall instrument. This process ensures that each item contributes meaningfully to the measurement of the construct.
Observational Measures and Reliability
For observational measures, equivalence reliability is assessed through interrater reliability. This form of reliability ensures that ratings from different observers are consistent and not influenced by individual rater variability.
Kappa Statistic: The kappa statistic is commonly used to assess interrater reliability. It measures the agreement between raters while controlling for chance agreement. Kappa values range from -1 (no agreement) to 1 (perfect agreement), with higher values indicating better reliability.
Generalizability Theory (G Theory)
Recent proposals for test consistency have introduced generalizability theory (G theory) as an alternative to classical measurement theory. G theory offers a more comprehensive approach to estimating measurement error by considering multiple sources of random error in a single analysis.
Generalizability Coefficient: G theory calculates a generalizability coefficient that reflects the reliability of measurements across different conditions and sources of error. Proponents of G theory argue that it provides a more flexible and global approach to understanding measurement consistency compared to classical reliability measures.
Conclusion
Reliability is a crucial aspect of classical measurement theory, ensuring that measurement instruments consistently produce accurate and dependable results. By examining stability, equivalence, and internal consistency, researchers and practitioners can evaluate the reliability of their instruments and enhance the quality of their measurements. While Cronbach’s alpha remains a prevalent method for assessing internal consistency, it is essential to consider its limitations and complement it with other methods and theories, such as generalizability theory, to achieve a comprehensive understanding of measurement reliability.
Read More:
https://nurseseducator.com/didactic-and-dialectic-teaching-rationale-for-team-based-learning/
https://nurseseducator.com/high-fidelity-simulation-use-in-nursing-education/
First NCLEX Exam Center In Pakistan From Lahore (Mall of Lahore) to the Global Nursing
Categories of Journals: W, X, Y and Z Category Journal In Nursing Education
AI in Healthcare Content Creation: A Double-Edged Sword and Scary
Social Links:
https://www.facebook.com/nurseseducator/
https://www.instagram.com/nurseseducator/